

一、卷积神经网络系列模型发展综述
- 1.LeNet
- 2.AlexNet
- 3.VGG
- 4.GoogleNet
- 5.ResNet
- 6.DenseNet
- 7.Non-Local Networks
- 8.Deformable Convolutional Networks
- 9.Dilated Convolutional Networks
- 10.SENET
01 卷积神经网络的基本组成
在不同的资料中,对CNN的组成部分有着不同的描述。不过,CNN的基本组成成分是比较一致的,一般CNN含有三种类型的神经网络层:
- 卷积层(Convolutions layer):学习输入数据的特征表示,卷积层由很多的卷积核(convolutional kernel)组成,卷积核用来计算不同的特征图(feature map)。激活函数(activation function)给CNN卷积神经网络引入了非线性,常用的有sigmoid,tanh,relu函数。
- 池化层(Pooling layer):降低卷积层输出的特征向量,同时改善结果,使结构不容易出现过拟合。典型的操作包括平均池化和最大池化。通过卷积层和池化层,可以获得更多的抽象特征。
- 全连接层(Full connected layer):将卷积层和池化层堆叠起来以后,就能够形成一层或者多层全连接层,这样就能够实现高阶的推理能力,在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。sigmoid/tanh常见于全连接层,relu常见于卷积层。
卷积神经网络(CNN)是一种常见的深度学习架构,受生物自然视觉认知机制启发而来。
二、 LeNet-5模型的提出
在1998年,LeCun提出文章《Gradient-based Learning applied to document recognition》。
http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
01 LeNet-5模型结构

LeNet-5模型共有7层。
-
第一层:卷积层
接受32321的图像输入。本层包含6个大小为55,步长为11的卷积核,padding类型为valid。输出神经元为28286.
-
第二层:池化层
对上一层的输出做22的max pooling,输出神经元为1414*6。
-
第三层:卷积层
接受14146的输入。本层有16个大小为55,步长为11的卷积核,padding类型为valid。输出神经元为101016.
-
第四层:池化层
对上一层的输出做22的max pooling,输出神经元为55*16
-
第五层:全连接层
本层将上层的5516的神经元展开作为输入,本层包含120个神经元。
-
第六层:全连接层
本层包含84个神经元
-
第七层:全连接层
本层包含10个神经元,分别代表数字0到9.
-
第八层:激活函数
前7层论文采用的tanh激活函数,输出层论文采用的是Guasian Connection.
02 LeNet-5代码实现
# 导包
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense,Flatten,Conv2D,MaxPool2D
from keras.optimizers import SGD
from keras.utils import to_categorical
Using TensorFlow backend.
# 加载数据集
(x_train,y_train),(x_test,y_test) = mnist.load_data()
print(x_train.shape,y_train.shape,x_test.shape,y_test.shape)
(60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
# 数据集的预处理操作
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
# 标签变为one-hot编码的形式
y_train = to_categorical(y_train,num_classes=10)
y_test = to_categorical(y_test,num_classes=10)
# LeNet-5模型的定义
model = Sequential()
model.add(Conv2D(filters = 6,
kernel_size = (5,5),
padding = "valid",
input_shape = (28,28,1),
activation = "tanh"))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Conv2D(filters = 16,
kernel_size = (5,5),
padding = "valid",
activation = "tanh"))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(120,activation = "tanh"))
model.add(Dense(84,activation = "tanh"))
model.add(Dense(10,activation = "softmax"))
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 120) 30840
_________________________________________________________________
dense_2 (Dense) (None, 84) 10164
_________________________________________________________________
dense_3 (Dense) (None, 10) 850
=================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
_________________________________________________________________
# 训练模型
sgd = SGD(lr = 0.05,
decay = 1e-6,
momentum = 0.9,
nesterov= True)
model.compile(optimizer = sgd,
loss = "categorical_crossentropy",
metrics = ["accuracy"])
model.fit(x_train,
y_train,
batch_size = 514,
epochs = 8,
verbose = 1,
validation_data=(x_test,y_test),
shuffle = True)
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Train on 60000 samples, validate on 10000 samples
Epoch 1/8
60000/60000 [==============================] - 11s 179us/step - loss: 0.3972 - accuracy: 0.8807 - val_loss: 0.1354 - val_accuracy: 0.9594
Epoch 2/8
60000/60000 [==============================] - 10s 167us/step - loss: 0.1165 - accuracy: 0.9645 - val_loss: 0.0901 - val_accuracy: 0.9713
Epoch 3/8
60000/60000 [==============================] - 10s 166us/step - loss: 0.0925 - accuracy: 0.9713 - val_loss: 0.0962 - val_accuracy: 0.9705
Epoch 4/8
60000/60000 [==============================] - 10s 165us/step - loss: 0.0800 - accuracy: 0.9757 - val_loss: 0.0697 - val_accuracy: 0.9779
Epoch 5/8
60000/60000 [==============================] - 10s 162us/step - loss: 0.0648 - accuracy: 0.9805 - val_loss: 0.0825 - val_accuracy: 0.9738
Epoch 6/8
60000/60000 [==============================] - 10s 168us/step - loss: 0.0615 - accuracy: 0.9806 - val_loss: 0.0602 - val_accuracy: 0.9809
Epoch 7/8
60000/60000 [==============================] - 10s 161us/step - loss: 0.0568 - accuracy: 0.9828 - val_loss: 0.0550 - val_accuracy: 0.9822
Epoch 8/8
60000/60000 [==============================] - 9s 156us/step - loss: 0.0466 - accuracy: 0.9856 - val_loss: 0.0510 - val_accuracy: 0.9832
<keras.callbacks.callbacks.History at 0x19b6145f4a8>
三、 AlexNet提出
AlexNet是Hinton和他的学生Alex在2012年设计的网络,并获得了当年的ImageNet的竞赛冠军。
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
01 AlexNet的模型结构

首先上面这幅图可以分为上下两个部分的网络,正如论文中提到的这两部分网络是分别两个GPU的,只有到了特定的网络层后才需要两块GPU交互。这种设置完全就是利用两个GPU来提高运算效率,在网络结构上差异并不是很大,所以我们可以直接当成一块GPU来看待。
那么AlexNet的整个网络结构就是由5个卷积层和3个全连接层组成的,深度总共8层。
上图中的输入是224×224,不过经过计算(224−11)/4=54.75并不是论文中的55×55,而使用227×227作为输入,则(227−11)/4=55
-
卷积层C1
-
该层的处理流程是: 卷积–>ReLU–>池化–>归一化。
-
卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
-
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
-
池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)
-
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
-
卷积层C2
-
该层的处理流程是:卷积–>ReLU–>池化–>归一化
-
卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为27×27 times128. ((27+2∗2−5)/1+1=27)
-
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
-
池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
-
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
-
卷积层C3
-
该层的处理流程是: 卷积–>ReLU
-
卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384
-
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
-
卷积层C4
-
该层的处理流程是: 卷积–>ReLU该层和C3类似。
-
卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192
-
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
-
卷积层C5
-
该层处理流程为:卷积–>ReLU–>池化
-
卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
-
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
-
池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
-
全连接层FC6
-
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
-
卷积->全连接: 输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
-
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
-
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
-
全连接层FC7
-
流程为:全连接–>ReLU–>Dropout
-
全连接,输入为4096的向量
-
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
-
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
-
全连接层FC8
-
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
02 AlexNet模型特点
-
ReLU Nonlinearity(Rectified Linear Unit)
在过去,神经网络的激活函数通常是sigmoid或者tanh函数,这两种函数最大的缺点就是其饱和性。当输入的x过大或过小时,函数的输出会非常接近于+1于-1,在这里斜率会非常小,那么在训练时引用梯度下降时,其饱和性会使梯度非常小,严重降低了网络的训练速度。
而Relu函数表示为max(0,x),当x>0会输出x,斜率恒为1,在实际使用时,神经网络的收敛速度要快过传统的激活函数10倍。 -
Training on multiple GPUs
利用多个GPU进行分布式计算
- Local respnse normalization
在使用饱和型的激活函数时,通常需要对输入进行归一化处理,以利用激活函数在0附近的线性特性和非线性特性,并避免饱和。但对于ReLU函数,不需要输入归一化。然而Alex等人发现LRN这种归一化方式可以帮助提高网络的泛化性能。
LRN的作用就是,对位置(x,y)处的像素计算其余几个相邻的kernel maps的像素值的和,并除以这个和来归一化。kernel maps的顺序可以是任意的,在训练开始前确定顺序即可。
Hinton等人认为LRN层模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值相对更大,提高模型的泛化能力。但是后来的论文如提出VGG网络的文章中证明,LRN对CNN并没有什么作用,反而增加了计算复杂度,因此,这一技术也不再使用了。
- Overlapping pooling
池化层是CNN中非常重要的一层,可以起到提取主要特征,减少特征图尺寸的作用,对加速CNN计算非常重要,然而通常池化的大小与步进被设置为相同的大小,当池化的大小大于步进时,就成为了overlapping pooling。
在先前的LeNet中的池化是不重叠的,即池化的窗口大小和步长是相等的。在AlexNet中使用的池化却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3*3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合。
- Reducing Overfitting
AlexNet中有6kw个参数,非常容易产生过拟合现象,而AlexNet中采用了两种方式来对抗过拟合。
Data augmentation
对抗过拟合最简单有效的方法就是扩大训练集的大小,AlexNet使用了两种增加训练集大小的方式。
1.Image translations and horizontal reflections.对原始的256*256大小的图片随机裁剪为224*224大小,并进行随机翻转,这两种操作相当于把训练集扩大了32*32*2=2048倍。在测试时,AlexNet把输入图片与其水平翻转在四个角处于正中心共五个地方各裁剪下224*224大小的子图,即共裁剪出10个子图,均送入AlexNet中,并把10个softmax输出求平均。如果没有这些操作,AlexNet将出现严重的过拟合,使网络的深度不能达到这么深。
2.Altering the intensities of the RGB channel. AlexNet对RGB通道使用了PCA(主成分分析),对每个训练图片的每个像素,提取出RGB三个通道的特征向量与特征值,对每个特征值乘以α,α是一个均值0.1且方差服从高斯分布的随机变量。
Dropout
Dropout是神经网络中一种非常有效的减少过拟合的方法,对每个神经元设置一个一个keep_prob用来表示这个神经元被保留的概率,如果神经元没被保留,换句话说这个神经元被"dropout"了,那么这个神经元的输出被设置为0,在残差反向传播时,传播到该神经元的值也为0,因此可以认为神经网络中不存在这个神经元;而在下次迭代中,所有神经元将会根据keep_prob被重新随机dropout。相当于每次迭代,神经网络的拓扑结构都会有所不同,这就会迫使神经网络不会过度依赖某几个神经元或者说某些特征。因此,神经元会被迫去学习更具有鲁棒性的特征。
03 AlexNet源码实现
AlexNet模型建立在千分类的问题上,其算力对计算机要求很高。这里为了简单复现,使用了Tensorflow的数据集oxflower17,此数据集对花朵进行17分类,每个分类有80张图片。
# 导包
import keras
from keras.models import Sequential
from keras.layers import Dense,Activation,Dropout,Flatten,Conv2D,MaxPool2D
from keras.layers.normalization import BatchNormalization
import numpy as np
np.random.seed(1000)
Using TensorFlow backend.
# 获取数据
import tflearn.datasets.oxflower17 as oxflower17
x,y = oxflower17.load_data(one_hot=True)
curses is not supported on this machine (please install/reinstall curses for an optimal experience)
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\helpers\summarizer.py:9: The name tf.summary.merge is deprecated. Please use tf.compat.v1.summary.merge instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\helpers\trainer.py:25: The name tf.summary.FileWriter is deprecated. Please use tf.compat.v1.summary.FileWriter instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\collections.py:13: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\config.py:123: The name tf.get_collection is deprecated. Please use tf.compat.v1.get_collection instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\config.py:129: The name tf.add_to_collection is deprecated. Please use tf.compat.v1.add_to_collection instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\tflearn\config.py:131: The name tf.assign is deprecated. Please use tf.compat.v1.assign instead.
# 定义AlexNet模型
model = Sequential()
# 1block
model.add(Conv2D(filters = 97,
kernel_size = (11,11),
strides = (4,4),
padding = "valid",
input_shape = (224,224,3)))
model.add(Activation("relu"))
model.add(MaxPool2D(pool_size = (2,2),
strides = (2,2),
padding = "valid"))
model.add(BatchNormalization())
# 2block
model.add(Conv2D(filters = 256,
kernel_size = (11,11),
strides = (1,1),
padding = "valid"))
model.add(Activation("relu"))
model.add(MaxPool2D(pool_size = (2,2),
strides = (2,2),
padding = "valid"))
model.add(BatchNormalization())
# 3 block
model.add(Conv2D(filters = 384,
kernel_size = (3,3),
strides = (1,1),
padding = "valid"))
model.add(Activation("relu"))
model.add(BatchNormalization())
# 4 block
model.add(Conv2D(filters = 384,
kernel_size = (3,3),
strides = (1,1),
padding = "valid"))
model.add(Activation("relu"))
model.add(BatchNormalization())
# 5 block
model.add(Conv2D(filters = 256,
kernel_size = (3,3),
strides = (1,1),
padding = "valid"))
model.add(Activation("relu"))
model.add(MaxPool2D(pool_size = (2,2),
strides = (2,2),
padding = "valid"))
model.add(BatchNormalization())
# 6 dense
model.add(Flatten())
model.add(Dense(4096, input_shape=(224*224*3,)))
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(BatchNormalization())
# 7 dense
model.add(Dense(4096))
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(BatchNormalization())
# 8 dense
model.add(Dense(17))
model.add(Activation("softmax"))
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 54, 54, 97) 35308
_________________________________________________________________
activation_1 (Activation) (None, 54, 54, 97) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 27, 27, 97) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 27, 27, 97) 388
_________________________________________________________________
conv2d_2 (Conv2D) (None, 17, 17, 256) 3004928
_________________________________________________________________
activation_2 (Activation) (None, 17, 17, 256) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 256) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 8, 8, 256) 1024
_________________________________________________________________
conv2d_3 (Conv2D) (None, 6, 6, 384) 885120
_________________________________________________________________
activation_3 (Activation) (None, 6, 6, 384) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 6, 6, 384) 1536
_________________________________________________________________
conv2d_4 (Conv2D) (None, 4, 4, 384) 1327488
_________________________________________________________________
activation_4 (Activation) (None, 4, 4, 384) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 4, 4, 384) 1536
_________________________________________________________________
conv2d_5 (Conv2D) (None, 2, 2, 256) 884992
_________________________________________________________________
activation_5 (Activation) (None, 2, 2, 256) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 1, 1, 256) 0
_________________________________________________________________
batch_normalization_5 (Batch (None, 1, 1, 256) 1024
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 1052672
_________________________________________________________________
activation_6 (Activation) (None, 4096) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
batch_normalization_6 (Batch (None, 4096) 16384
_________________________________________________________________
dense_2 (Dense) (None, 4096) 16781312
_________________________________________________________________
activation_7 (Activation) (None, 4096) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 4096) 0
_________________________________________________________________
batch_normalization_7 (Batch (None, 4096) 16384
_________________________________________________________________
dense_3 (Dense) (None, 17) 69649
_________________________________________________________________
activation_8 (Activation) (None, 17) 0
=================================================================
Total params: 24,079,745
Trainable params: 24,060,607
Non-trainable params: 19,138
_________________________________________________________________
# compile
model.compile(loss = "categorical_crossentropy",
optimizer = "adam",
metrics = ["accuracy"])
# train
model.fit(x,
y,
batch_size = 32,
epochs = 8,
verbose = 1,
validation_split = 0.3,
shuffle = True)
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Train on 951 samples, validate on 409 samples
Epoch 1/8
951/951 [==============================] - 98s 103ms/step - loss: 4.1242 - accuracy: 0.2177 - val_loss: 74.8161 - val_accuracy: 0.0685
Epoch 2/8
951/951 [==============================] - 100s 105ms/step - loss: 2.7997 - accuracy: 0.3091 - val_loss: 12.2919 - val_accuracy: 0.1345
Epoch 3/8
951/951 [==============================] - 94s 99ms/step - loss: 2.3698 - accuracy: 0.3544 - val_loss: 7.1330 - val_accuracy: 0.1858
Epoch 4/8
951/951 [==============================] - 100s 105ms/step - loss: 2.1398 - accuracy: 0.4206 - val_loss: 3.2262 - val_accuracy: 0.2885
Epoch 5/8
951/951 [==============================] - 96s 101ms/step - loss: 2.0635 - accuracy: 0.4385 - val_loss: 2.7424 - val_accuracy: 0.3594
Epoch 6/8
951/951 [==============================] - 92s 96ms/step - loss: 1.9173 - accuracy: 0.4448 - val_loss: 2.6016 - val_accuracy: 0.3423
Epoch 7/8
951/951 [==============================] - 89s 94ms/step - loss: 1.9253 - accuracy: 0.4753 - val_loss: 3.7909 - val_accuracy: 0.3374
Epoch 8/8
951/951 [==============================] - 89s 94ms/step - loss: 1.5822 - accuracy: 0.5310 - val_loss: 3.0874 - val_accuracy: 0.3521
<keras.callbacks.callbacks.History at 0x257cb057a20>
四、 VGGNet的提出
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发的深度卷积神经网络,并在2014年举办的ILSVRC中获得了定位任务第一名和分类任务第二名的好成绩。它继承了AlexNet的思路,一样由5个卷积层和3个全连接层组成。只不过在每个卷积层中进行2~4次连续卷积。
- 在VGGNet中,卷积层使用的卷积核均为3x3,步长为1.卷积之后都要进行最大池化Max pooling,池化核为2x2,步长为2.
- 所有的隐藏层都使用ReLU激活函数
- 全连接层1,2使用Dropout来避免过拟合,概率为0.5
多次重复使用同一大小的卷积核来提取更复杂和更具有表达性的特征
https://arxiv.org/abs/1409.1556
01 VGGNet的模型结构

- 卷积核采用3*3
- VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部都会连接一共最大池化层用来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多:64-128-256-512-512.其中经常出现多个完全一样的3*3的卷积层堆叠在一起的情况,这其实是非常有用的设计。
- 两个3x3的卷积层串联相当于一个1个5x5的卷积层,即一个像素会跟周围5*5的像素产生关联,可以说感受野的大小为5x5.
- 三个3x3的卷积层串联的效果则相当于1个7x7的卷积层。除此之外,3个串联的3*3的卷积层,拥有比1个7x7的卷积层更少的参数量,只有后者的一半。最重要的是,3个3x3的卷积层拥有比1个7x7的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
02 VGGNet模型论文观点
- 1.用多层的卷积层组合配以小尺寸的滤波器,能实现大尺寸滤波器的感受野的同时,还能使参数数量更少;
- 2.表示层深度的增加,能有效提升模型的性能;
- 3.模型融合的性能优于单模型的性能;
- 4.训练期间分阶段降低学习率有助模型收敛;
03 VGGNet-16的结构

04 VGGNet-16代码实现
# 导包
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense,Dropout,Activation,Flatten,Conv2D,MaxPooling2D
from keras.utils import to_categorical
from keras import optimizers
from keras.optimizers import SGD
# 导入数据
(x_train,y_train),(x_test,y_test) = cifar10.load_data()
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
y_train = to_categorical(y_train,10)
y_test = to_categorical(y_test,10)
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 29s 0us/step
# 定义VGG16模型
model = Sequential()
# block1
model.add(Conv2D(filters = 64,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block1_conv1",
input_shape = (32,32,3)))
model.add(Conv2D(filters = 64,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block1_conv2"))
model.add(MaxPooling2D(pool_size = (2,2),
strides = (2,2),
name = "block1_pool"))
# block2
model.add(Conv2D(filters = 128,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block2_conv1"))
model.add(Conv2D(filters = 128,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block2_conv2"))
model.add(MaxPooling2D(pool_size = (2,2),
strides = (2,2),
name = "block2_pool"))
# block3
model.add(Conv2D(filters = 256,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block3_conv1"))
model.add(Conv2D(filters = 256,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block3_conv2"))
model.add(Conv2D(filters = 256,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block3_conv3"))
model.add(MaxPooling2D(pool_size = (2,2),
strides = (2,2),
name = "block3_pool"))
# block4
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block4_conv1"))
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block4_conv2"))
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block4_conv3"))
model.add(MaxPooling2D(pool_size = (2,2),
strides = (2,2),
name = "block4_pool"))
# block5
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block5_conv1"))
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block5_conv2"))
model.add(Conv2D(filters = 512,
kernel_size = (3,3),
activation = "relu",
padding = "same",
name = "block5_conv3"))
model.add(MaxPooling2D(pool_size = (2,2),
strides = (2,2),
name = "block5_pool"))
model.add(Flatten())
model.add(Dense(4096,activation="relu",name="fc1"))
model.add(Dropout(0.5))
model.add(Dense(4096,activation="relu",name="fc2"))
model.add(Dropout(0.5))
model.add(Dense(10,activation="softmax",name="prediction"))
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 512) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 2101248
_________________________________________________________________
dropout_3 (Dropout) (None, 4096) 0
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_4 (Dropout) (None, 4096) 0
_________________________________________________________________
prediction (Dense) (None, 10) 40970
=================================================================
Total params: 33,638,218
Trainable params: 33,638,218
Non-trainable params: 0
_________________________________________________________________
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="categorical_crossentropy",
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train,
y_train,
epochs=8,
batch_size=64,
validation_split=0.3,
verbose=1)
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Train on 35000 samples, validate on 15000 samples
Epoch 1/8
35000/35000 [==============================] - 1801s 51ms/step - loss: 2.2628 - accuracy: 0.1228 - val_loss: 2.0258 - val_accuracy: 0.1864
Epoch 2/8
35000/35000 [==============================] - 1737s 50ms/step - loss: 1.8117 - accuracy: 0.2843 - val_loss: 1.5979 - val_accuracy: 0.3885
Epoch 3/8
35000/35000 [==============================] - 1724s 49ms/step - loss: 1.4809 - accuracy: 0.4505 - val_loss: 1.3295 - val_accuracy: 0.5201
Epoch 4/8
35000/35000 [==============================] - 4062s 116ms/step - loss: 1.1633 - accuracy: 0.5833 - val_loss: 1.0005 - val_accuracy: 0.6498
Epoch 5/8
35000/35000 [==============================] - 1772s 51ms/step - loss: 0.9778 - accuracy: 0.6570 - val_loss: 0.9629 - val_accuracy: 0.6710
Epoch 6/8
35000/35000 [==============================] - 1832s 52ms/step - loss: 0.8202 - accuracy: 0.7206 - val_loss: 0.8424 - val_accuracy: 0.7109
Epoch 7/8
35000/35000 [==============================] - 1886s 54ms/step - loss: 0.6917 - accuracy: 0.7658 - val_loss: 0.8114 - val_accuracy: 0.7312
Epoch 8/8
35000/35000 [==============================] - 1760s 50ms/step - loss: 0.5947 - accuracy: 0.7989 - val_loss: 0.7796 - val_accuracy: 0.7450
<keras.callbacks.callbacks.History at 0x17e3bef6f28>
05 VGGNet-16封装
from keras.applications import VGG16
model = VGG16(weights="imagenet",include_top=False)
model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, None, None, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, None, None, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, None, None, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, None, None, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, None, None, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, None, None, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, None, None, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, None, None, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, None, None, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, None, None, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, None, None, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, None, None, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, None, None, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, None, None, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
五、 GoogLeNet的提出
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同点就是层次更深了。VGG继承了LeNet以及AlexNet的一些框架架构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小确比AlexNet和VGG小很多,GoogLeNet参数为500万个,AlexNet参数个数是GoogLeNet的12倍,VGGNet参数是AlexNet的3倍,因此在内存或计算资源有限时,GoogLeNet是比较好的选择;从模型结果来看,GoogLeNet的性能更加优越。
[v1] Going Deeper withConvolutions, 6.67% test error,2014.9
论文地址:http://arxiv.org/abs/1409.4842
[v2] Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error,2015.2
论文地址:http://arxiv.org/abs/1502.03167
[v3] Rethinking theInception Architecture for Computer Vision, 3.5%test error,2015.12
论文地址:http://arxiv.org/abs/1512.00567
[v4] Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error,2016.2
论文地址:http://arxiv.org/abs/1602.07261
01 GoogLeNet的发展
Inception的作用就是替代了人工确定卷积层中过滤器的类型或者是否创建卷积层和池化层,让网络自己学习它具体需要什么参数。
Inception V1
Inception V1中精心设计了Inception Module提高了参数的利用率;Inception V1去除了模型最后的全连接层,用全局平局池化层将图片尺寸变为1*1,在先前的网络中,全连接层占据了网络的大部分参数,很容易产生过拟合现象。

Inception V2
Inception V2学习了VGGNet,用两个3*3的卷积代替5*5的大卷积核(降低参数量的同时减轻了过拟合),同时还提出了Batch Normalization方法.BN是一个非常有效的正则化方法,可以让大型卷积神经网络的训练速度加快很多倍,同时收敛后的分类准确率可以得到大幅度提高。
BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化处理,使输出规范化到(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。BN论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,可以有效解决这个问题,学习速率可以增大很多倍,达到之前的准确率需要迭代的次数需要1/14,训练时间大大缩短
当然,在使用BN时,需要一些调整:
增大学习率并加快学习衰减速度以适应BN规范后的数据去除Dropout并减轻L2正则去除LRN更彻底地对训练样本进行shuffle减少数据增强过程中对数据的光学畸变
Inception v3
Inception V3主要在两个方面改造:
-
引入了Factorization into small convolutions的思想,
将一个较大的二维卷积拆成两个较小的一维卷积,比如将7*7卷积拆成1*7卷积核7*1卷积(下图是3*3拆分成1*3和3*1的示意图)。一方面节约了大量参数,加速运算并减去过拟合,同时增加了一层非线性扩展模型的表达能力。

-
另一方面,Inception V3优化了Inception Module的结构,现在Inception Module有3535、1717和8*8三种不同的结构。

Inception v4
Inception V4相比V3主要是结合微软的ResNet,发现ResNet的结构可以极大地加速训练,同时性能也有提升。
02 Inception模块实现
import keras
from keras.layers import Conv2D,MaxPooling2D,Input
input_img = Input(shape=(256,256,3))
tower_1 = Conv2D(64,(1,1),padding="same",activation="relu")(input_img)
tower_1 = Conv2D(64,(3,3),padding="same",activation="relu")(tower_1)
tower_2 = Conv2D(64,(1,1),padding="same",activation="relu")(input_img)
tower_2 = Conv2D(64,(5,5),padding="same",activation="relu")(tower_2)
tower_3 = MaxPooling2D((3,3),strides=(1,1),padding="same")(input_img)
tower_3 = Conv2D(64,(1,1),padding="same",activation="relu")(tower_3)
output = keras.layers.concatenate([tower_1,tower_2,tower_3],axis=1)
03 Inception V3调用
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense,GlobalAveragePooling2D
from keras import backend as K
# 构建不带分类器的预训练模型
base_model = InceptionV3(weights="imagenet",include_top=False)
# 添加全局平均池化层
x = base_model.output
x = GlobalAveragePooling2D()(x)
# 添加一个全连接层
x = Dense(1024,activation="relu")(x)
# 添加一个分类器,假设有100个类
predictions = Dense(100,activation="softmax")(x)
# 构建完整的模型
model = Model(input=base_model.input,outputs=predictions)
# 首先,我们只训练顶部的几层
# 锁住所有的inception v3的卷积层
for layer in base_model.layers:
layer.trainable = False
# 编译模型
model.compile(optimizer = "rmsprop",
loss = "categorical_crossentropy",
metrics = ["accuracy"])
C:\software\anaconda\lib\site-packages\ipykernel_launcher.py:21: UserWarning: Update your `Model` call to the Keras 2 API: `Model(outputs=Tensor("de..., inputs=Tensor("in...)`
# 在新的数据集上训练几代
model.fit_generator()
# 现在顶层应该训练好来,让我们开始微调inception v3的卷积层
# 我们会锁住底下的几层,然后训练其余的顶层
# 让我们看看每一层的名字和序号,看看应该锁多少层
for i,layer in enumerate(base_model.layers):
print(i,layer.name)
0 input_4
1 conv2d_105
2 batch_normalization_95
3 activation_95
4 conv2d_106
5 batch_normalization_96
6 activation_96
7 conv2d_107
8 batch_normalization_97
9 activation_97
10 max_pooling2d_7
11 conv2d_108
12 batch_normalization_98
13 activation_98
14 conv2d_109
15 batch_normalization_99
16 activation_99
17 max_pooling2d_8
18 conv2d_113
19 batch_normalization_103
20 activation_103
21 conv2d_111
22 conv2d_114
23 batch_normalization_101
24 batch_normalization_104
25 activation_101
26 activation_104
27 average_pooling2d_10
28 conv2d_110
29 conv2d_112
30 conv2d_115
31 conv2d_116
32 batch_normalization_100
33 batch_normalization_102
34 batch_normalization_105
35 batch_normalization_106
36 activation_100
37 activation_102
38 activation_105
39 activation_106
40 mixed0
41 conv2d_120
42 batch_normalization_110
43 activation_110
44 conv2d_118
45 conv2d_121
46 batch_normalization_108
47 batch_normalization_111
48 activation_108
49 activation_111
50 average_pooling2d_11
51 conv2d_117
52 conv2d_119
53 conv2d_122
80 batch_normalization_119
81 batch_normalization_120
82 activation_114
83 activation_116
84 activation_119
300 batch_normalization_180
301 activation_182
302 activation_183
303 activation_186
304 activation_187
305 batch_normalization_188
306 activation_180
307 mixed9_1
308 concatenate_5
309 activation_188
310 mixed10
# 我们选择训练最上面的两个Inception block
# 也就是锁住前面的249层,然后放开之后的层
for layer in model.layers[:249]:
layer.trainable = False
for layer in model.layers[249:]:
layer.trainable = True
# 我们需要重新编译模型,才能使上面的修改生效
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),loss="categorical_crossentropy",metrics=["accuracy"])
# 继续训练模型,这次训练最后两个Inception block和两个全连接层
model.fit_generator()
六、 ResNet的提出
MSRA(微软亚洲研究院)何凯明团队的深度残差网络(Deep Residual Network)在2015年的ImageNet上取得冠军,该网络简称为ResNet,层数达到了152层,top-5错误率降到了3.57.
https://arxiv.org/pdf/1512.03385.pdf
ResNet指出,在许多的数据上都显示出一个普遍现象:增加网络深度到一定程度时,更深的网络意味着更高的训练误差。
误差升高的原因是网络越深,梯度消失的现象就越明显,所以在反向传播的时候,无法有效的把梯度更新到前面的网络层,靠前的网络层参数无法更新,导致训练和测试效果变差。
ResNet面临的问题就是怎么样在增加网络深度的情况下可以有效解决梯度消失的问题。
01 残差网络
ResNet中解决深层网络梯度消失的问题的核心结构是残差网络

残差网络增加了一个identity mapping(恒等映射),把当前输出直接传输给下一层网络(全部是1:1传输,不增加额外的参数),相当于走了一个捷径,跳过了本层运算,这个直接连接命名为"skip connection"。同时在反向传播过程中,也是将下一层网络的梯度直接传递给上一层网络,这样就解决了深层网络的梯度消失问题。
02 残差结构的实现
import keras
from keras.layers import Conv2D,Input
x = Input(shape=(224,224,3))
y = Conv2D(3,(3,3),padding="same")(x)
z = keras.layers.add([x,y])
03 ResNet实现
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
model = ResNet50(weights="imagenet")
img_path = "elephant.jpg"
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
# decode the results into a list of tuples (class, description, probability)
# (one such list for each sample in the batch)
print("Predicted:", decode_predictions(preds, top=3)[0])
Predicted: [('n02504458', 'African_elephant', 0.4616896), ('n01871265', 'tusker', 0.38391447), ('n02504013', 'Indian_elephant', 0.15430869)]
七、 DenseNet的提出
论文:Densely Connected Convolutional Networks
论文链接:https://arxiv.org/pdf/1608.06993.pdf
在本篇论文中提出了一种不同于ResNet的深层卷积神经网络,称为DenseNet。
为了在数据集上获得比较好的效果,主要的做法有两种:
- 设计更宽的网络:代表:GoogLeNet,FractalNets
- 设计更深的网络:代表:HighwayNet,ResNet
而本论文的作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。这个设计思想是feature reuse
01 DenseNet设计思想
DenseNet的设计思想是feature reuse,也就是特征再利用。

这个图很直观明了展示了DenseNet feature reuse的设计思想。这是一个dense block,是DenseNet中的一个子模块,每一层的输入都包含了前面所有的层(通过concatenate的方式)。

DenseNet的几个优点:
- 减轻了vanishing-gradient(梯度消失)
- 加强了feature的传递
- 更加有效的利用了feature
- 一定程度上减少了参数数量。
02 DenseNet的实现

Conv_block:
卷积操作,按照论文的说法,这里应该是一个组合函数,分别为:BatchNormalization、ReLU和3*3Conv
import keras
from keras.layers import *
from keras.models import *
from keras import backend as K
from keras.regularizers import l2
Using TensorFlow backend.
def conv_block(ip, nb_filter, bottleneck=False, dropout_rate=None, weight_decay=1e-4):
''' Apply BatchNorm, Relu, 3x3 Conv2D, optional bottleneck block and dropout
Args:
ip: Input keras tensor
nb_filter: number of filters
bottleneck: add bottleneck block
dropout_rate: dropout rate
weight_decay: weight decay factor
Returns: keras tensor with batch_norm, relu and convolution2d added (optional bottleneck)
'''
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(ip)
x = Activation('relu')(x)
if bottleneck:
inter_channel = nb_filter * 4
x = Conv2D(inter_channel, (1, 1), kernel_initializer='he_normal', padding='same', use_bias=False,
kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = Conv2D(nb_filter, (3, 3), kernel_initializer='he_normal', padding='same', use_bias=False)(x)
if dropout_rate:
x = Dropout(dropout_rate)(x)
return x
其中的concat_axis表示特征轴,因为连接和BN都是对特征轴而言的。bottleneck表示是否使用瓶颈层,也就是使用1*1的卷积层将特征图的通道数进行压缩。
Transition_block
过渡层,用来连接两个dense_block.同时在最后一个dense_block的尾部不需要使用过渡层。按照论文的说法,过渡层由四部分组成:BatchNormalization、ReLU、11Conv和22Maxpooling。
def transition_block(ip, nb_filter, compression=1.0, weight_decay=1e-4):
'''Apply BatchNorm, ReLU, Conv2d, optional compressoin, dropout and Maxpooling2D
Args:
ip: keras tensor
nb_filter: number of filters
compression: caculated as 1 - reduction. Reduces the number of features maps in the transition block
dropout_rate: dropout rate
weight_decay: weight decay factor
Returns:
keras tensor, after applying batch_norm, relu-conv, dropout, maxpool
'''
concat_axis = 1 if K.image_data_format() == 'channels_first' else -1
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(ip)
x = Activation('relu')(x)
x = Conv2D(int(nb_filter * compression), (1, 1), kernel_initializer='he_normal', padding='same', use_bias=False,
kernel_regularizer=l2(weight_decay))(x)
x = AveragePooling2D((2, 2), strides=(2, 2))(x)
return x
其中的Conv2D操作实现了1x1的卷积操作,同时使用了compression_rate,也就是论文中说的压缩率,将通道数进行调整。
Dense_block:
此处使用循环实现了dense_block的密集连接。
def dense_block(x, nb_layers, nb_filter, growth_rate, bottleneck=False, dropout_rate=None, weight_decay=1e-4,
grow_nb_filters=True, return_concat_list=False):
'''Build a dense_block where the output of ench conv_block is fed t subsequent ones
Args:
x: keras tensor
nb_layser: the number of layers of conv_block to append to the model
nb_filter: number of filters
growth_rate: growth rate
bottleneck: bottleneck block
dropout_rate: dropout rate
weight_decay: weight decay factor
grow_nb_filters: flag to decide to allow number of filters to grow
return_concat_list: return the list of feature maps along with the actual output
Returns:
keras tensor with nb_layers of conv_block appened
'''
concat_axis = 1 if K.image_data_format() == 'channels_first' else -1
x_list = [x]
for i in range(nb_layers):
cb = conv_block(x, growth_rate, bottleneck, dropout_rate, weight_decay)
x_list.append(cb)
x = concatenate([x, cb], axis=concat_axis)
if grow_nb_filters:
nb_filter += growth_rate
if return_concat_list:
return x, nb_filter, x_list
else:
return x, nb_filter
其中的x = concatenate([x, cb], axis=concat_axis)操作使得x在每次循环中始终维护一个全局状态,第一次循环输入为x,输出为cb1,第二的输入为cb=[x, cb1],输出为cb2,第三次的输入为cb=[x, cb1, cb2],输出为cb3,以此类推。增长率growth_rate其实就是每次卷积时使用的卷积核个数,也就是最后输出的通道数。
Create_dense_net:
构建网络模型:
def create_dense_net(nb_classes, img_input, include_top, depth=40, nb_dense_block=3, growth_rate=12, nb_filter=-1,
nb_layers_per_block=[1], bottleneck=False, reduction=0.0, dropout_rate=None, weight_decay=1e-4,
subsample_initial_block=False, activation='softmax'):
''' Build the DenseNet model
Args:
nb_classes: number of classes
img_input: tuple of shape (channels, rows, columns) or (rows, columns, channels)
include_top: flag to include the final Dense layer
depth: number or layers
nb_dense_block: number of dense blocks to add to end (generally = 3)
growth_rate: number of filters to add per dense block
nb_filter: initial number of filters. Default -1 indicates initial number of filters is 2 * growth_rate
nb_layers_per_block: list, number of layers in each dense block
bottleneck: add bottleneck blocks
reduction: reduction factor of transition blocks. Note : reduction value is inverted to compute compression
dropout_rate: dropout rate
weight_decay: weight decay rate
subsample_initial_block: Set to True to subsample the initial convolution and
add a MaxPool2D before the dense blocks are added.
subsample_initial:
activation: Type of activation at the top layer. Can be one of 'softmax' or 'sigmoid'.
Note that if sigmoid is used, classes must be 1.
Returns: keras tensor with nb_layers of conv_block appended
'''
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
if type(nb_layers_per_block) is not list:
print('nb_layers_per_block should be a list!!!')
return 0
final_nb_layer = nb_layers_per_block[-1]
nb_layers = nb_layers_per_block[:-1]
if nb_filter <= 0:
nb_filter = 2 * growth_rate
compression = 1.0 - reduction
if subsample_initial_block:
initial_kernel = (7, 7)
initial_strides = (2, 2)
else:
initial_kernel = (3, 3)
initial_strides = (1, 1)
x = Conv2D(nb_filter, initial_kernel, kernel_initializer='he_normal', padding='same',
strides=initial_strides, use_bias=False, kernel_regularizer=l2(weight_decay))(img_input)
if subsample_initial_block:
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
for block_index in range(nb_dense_block - 1):
x, nb_filter = dense_block(x, nb_layers[block_index], nb_filter, growth_rate, bottleneck=bottleneck,
dropout_rate=dropout_rate, weight_decay=weight_decay)
x = transition_block(x, nb_filter, compression=compression, weight_decay=weight_decay)
nb_filter = int(nb_filter * compression)
# 最后一个block没有transition_block
x, nb_filter = dense_block(x, final_nb_layer, nb_filter, growth_rate, bottleneck=bottleneck,
dropout_rate=dropout_rate, weight_decay=weight_decay)
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
if include_top:
x = Dense(nb_classes, activation=activation)(x)
return x
生成Model
input_shape = (224,224,3)
inputs = Input(shape=input_shape)
x = create_dense_net(nb_classes=1000, img_input=inputs, include_top=True, depth=169, nb_dense_block=4,
growth_rate=32, nb_filter=64, nb_layers_per_block=[6, 12, 32, 32], bottleneck=True, reduction=0.5,
dropout_rate=0.0, weight_decay=1e-4, subsample_initial_block=True, activation='softmax')
model = Model(inputs, x, name='densenet169')
print(model.summary())
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4074: The name tf.nn.avg_pool is deprecated. Please use tf.nn.avg_pool2d instead.
Model: "densenet169"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 112, 112, 64) 9408 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 112, 112, 64) 256 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 112, 112, 64) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 56, 56, 64) 0 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 56, 56, 64) 256 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 56, 56, 64) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 56, 56, 128) 8192 activation_2[0][0]
batch_normalization_169 (BatchN (None, 7, 7, 1664) 6656 concatenate_82[0][0]
__________________________________________________________________________________________________
activation_169 (Activation) (None, 7, 7, 1664) 0 batch_normalization_169[0][0]
__________________________________________________________________________________________________
global_average_pooling2d_1 (Glo (None, 1664) 0 activation_169[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1000) 1665000 global_average_pooling2d_1[0][0]
==================================================================================================
Total params: 14,307,880
Trainable params: 14,149,480
Non-trainable params: 158,400
__________________________________________________________________________________________________
None
03 Keras迁移DenseNet
from keras.applications.densenet import DenseNet121
model = DenseNet121(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
Using TensorFlow backend.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
WARNING:tensorflow:From C:\software\anaconda\lib\site-packages\keras\backend\tensorflow_backend.py:4074: The name tf.nn.avg_pool is deprecated. Please use tf.nn.avg_pool2d instead.
model.summary()
Model: "densenet121"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 230, 230, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1/conv (Conv2D) (None, 112, 112, 64) 9408 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
conv1/bn (BatchNormalization) (None, 112, 112, 64) 256 conv1/conv[0][0]
__________________________________________________________________________________________________
conv1/relu (Activation) (None, 112, 112, 64) 0 conv1/bn[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, 114, 114, 64) 0 conv1/relu[0][0]
__________________________________________________________________________________________________
pool1 (MaxPooling2D) (None, 56, 56, 64) 0 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
conv2_block1_0_bn (BatchNormali (None, 56, 56, 64) 256 pool1[0][0]
__________________________________________________________________________________________________
conv2_block1_0_relu (Activation (None, 56, 56, 64) 0 conv2_block1_0_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_1_conv (Conv2D) (None, 56, 56, 128) 8192 conv2_block1_0_relu[0][0]
____________________________________________________________________________
bn (BatchNormalization) (None, 7, 7, 1024) 4096 conv5_block16_concat[0][0]
__________________________________________________________________________________________________
relu (Activation) (None, 7, 7, 1024) 0 bn[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 1024) 0 relu[0][0]
__________________________________________________________________________________________________
fc1000 (Dense) (None, 1000) 1025000 avg_pool[0][0]
==================================================================================================
Total params: 8,062,504
Trainable params: 7,978,856
Non-trainable params: 83,648
__________________________________________________________________________________________________
for i,layer in enumerate(model.layers):
print(i,layer)
0 <keras.engine.input_layer.InputLayer object at 0x000001E28E156E48>
1 <keras.layers.convolutional.ZeroPadding2D object at 0x000001E28E17C8D0>
2 <keras.layers.convolutional.Conv2D object at 0x000001E295CC14A8>
3 <keras.layers.normalization.BatchNormalization object at 0x000001E295CCC860>
4 <keras.layers.core.Activation object at 0x000001E295CCCD30>
180 <keras.layers.core.Activation object at 0x000001E2995C2390>
181 <keras.layers.convolutional.Conv2D object at 0x000001E299602908>
182 <keras.layers.merge.Concatenate object at 0x000001E29963DDD8>
八、 SENet的提出
论文:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/abs/1709.01507
Squeeze-and-Excitation Networks(简称SENet)是Momenta胡杰团队提出的新的网络结构,赢的最后一届ImageNet2017竞赛Image Classification任务多的冠军。
SENet是希望显式地建模特征通道之间的相互依赖关系,并未引入新的空间维度来进行特征通道间的融合,而是采用了一种全新的【特征重标定】的策略。具体来说,就是通过学习的方法来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并去抑制对当前任务用处不大的特征。
即引入了channel-wise的attention机制。
attention机制的目标:着重更有利于任务的信息,抑制无用/干扰/冗余信息。
01 SENet设计思想

上面是SE模块的示意图。给定一个输入x,其特征通道数为c_1,通过一系列卷积等一般变换后得到一个特征通道数为c_2的特征。与传统的CNN不一样的是,接下来主要是通过三个操作来重标定前面得到的特征。
- 首先是Squeeze操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个一维的实数。这个实数在某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配,它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
- 其次是Exciation操作,它是一个类似于循环神经网络中的门的机制。通过参数w来为每个特征通道生成权重,其中参数w被学习用来显式地建模特征通道间的相关性。
- 最后是一个Reweight的操作,将Excitation的输出的权重看做是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。

上图是将SE模块嵌入到Inception结构的一个示例。方框旁边的维度信息代表改成的输出。这里我们使用global average pooling作为Squeeze操作。紧跟着两个Fully Connected层组成一个Bottleneck结构去建模通道间的相关性,并输出和输入特征同样数目的通道。
首先将特征维度降低到输入的1/16,然后经过ReLu激活函数后再通过一个Fully Connected层升回到原来的维度。这样做比直接用一个Fully Connected层的好处在于:a.具有更多的非线性,可以更好的拟合通道间复杂的相关性;b.极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得0~1之间归一化的权重,最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。

SE模块还可以嵌入到含有skip-connections的模块中。上右图是将SE嵌入到ResNet模块中的一个例子,操作过程基本和SE-Inception一样,只不过是在Addition前对分支上Residual的特征进行了特征重标定。如果对Addition后主支上的特征进行重标定,由于在主干上存在0~1的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度弥散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过repeat方式叠加来构造的。由此可见,SE模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的building block单元中嵌入SE模块,我们可以获得不同种类的SENet。如SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2等。
02 SENet代码
# squeeze module的实现
squeeze = GlobalAveragePooling2D()(x)
excitation = Dense(units=out_dim//self.ratio)(squeeze)
excitation = self.activation(excitation)
excitation = Dense(units=out_dim)(excitation)
excitation = self.activation(excitation,"sigmoid")
excitation = Reshape((1,1,out_dim))(excitation)
scale = multiply([x,excitation])
# SE-Inception Module实现
def build_model(output_dims,input_shape=(224,224,3)):
inputs_dim = Input(input_shape)
x = Lambda(lambda x: x / 255.0)(inputs_dim) # 归一化处理
x = InceptionV3(include_top=False,
weights="imagenet",
input_tensor=None,
input_shape=(224,224,3),
pooling=max)(x)
squeeze = GlobalAveragePooling2D()(x)
excitation = Dense(units=2048//11)(squeeze)
excitation = Activation("relu")(excitation)
excitation = Dense(units=2048)(excitation)
excitation = Activation("sigmoid")(excitation)
excitation = Reshape((1,1,2048))(excitation)
scale = multiply([x,excitation])
x = GlobalAveragePooling2D()(scale)
dp_1 = Dropout(0.6)(x)
fc2 = Dense(out_dims)(dp_1)
fc2 = Activation("sigmoid")(fc2)
model = Model(inputs=inputs_dim,outputs=fc2)
return model
九、 CBAM的提出
论文:CBAM:Convolutional Block Attention Module
论文链接:https://arxiv.org/abs/1807.06521
这是ECCV2018的一篇文章,主要贡献为提出一个新的网络结构-简单但有效的注意力模块CBAM。给定一个中间特征图,我们分别沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。
在SENet论文中,提出了在feature map的通道上进行attention生成,然后与原来的feature map相乘。而在CBAM中,将attention同时运用到channel和spatial两个维度上,CBAM与SE Module一样,可以嵌入到目前大部分主流网络中,在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。
此外本文提出了影响卷积神经网络的几大因素:
- Depth:VGG,ResNet
- Width:GoogleNet
- Cardinality:Xception,ResNeXt
- Attention:channel attention,spatial attention
01 CBAM的设计思想

总之,CBAM在channel和spatial两个维度上引入了attention机制。
Channel attention module

将输入的feature map,分别经过基于width和height的global max pooling和global average pooling,然后分别经过MLP。将MLP输出的特征进行基于element wise的加和操作,最后再经过sigmoid激活操作,生成最终的channel attention feature map。将该channel attention feature map和input feature map做element wise乘法操作,生成spatial attention模块需要的输入特征。
Spatial attention module

将channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling和global average pooling,然后将这两个结果基于channel做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
02 CBAM模块的实现
def CBAM(input,reduction):
"""
@Convolutional Block Attention Module
"""
_, width, height, channel = input.get_shape() # (B,W,H,C)
# channel attention
x_mean = tf.reduce_mean(input,axis=(1,2).keepdims=True) # (B,1,1,C)
x_mean = tf.layers.conv2d(x_mean, channel // reduction, 1, activation=tf.nn.relu, name="CA1") # (B,1,1,C/r)
x_mean = tf.layers.conv2d(x_mean, channel, 1, name="CV2") # (B,1,1,C)
x_max = tf.reduce_max(input,axis=(1,2),keepdims=True) # (B,1,1,C)
x_max = tf..layers.conv2d(x_max,channel//reduction,1,activation=tf.nn.relu,name="CA1",reuse=True) #(B,1,1,C//r)
x_max = tf.layers.conv2d(x_max,channel,1,name="CA2",reuse=True) # (B,1,1,C) # reuse:Boolean类型,表示是否可以重复使用具有相同名字的前一层的权重。
x = tf.add(x_mean,x_max) # (B,1,1,C)
x = tf.nn.sigmoid(x) # (B,1,1,C)
x= tf.multiply(input,x) #(B,W,H,C)
# spatial attention
y_mean = tf.reduce_mean(x,axis=3,keepdims=True) # (B,W,H,1)
y_max = tf.reduce_max(x,axis=3,keepdims=True) # (B,W,H,1)
y = tf.concat([y_mean,y_max],axis=-1) # (B,W,H,2)
y = tf.layers.conv2d(y,1,7,padding="same",activation=tf.nn.sigmoid) # (B,W,H,1)
y = tf.multiply(x,y) # (B,W,H,C)
return y
from keras.layers import GlobalAveragePooling2D, GlobalMaxPooling2D, Reshape, Dense, multiply, Permute, Concatenate, Conv2D, Add, Activation, Lambda
from keras import backend as K
from keras.activations import sigmoid
def attach_attention_module(net, attention_module):
if attention_module == 'se_block': # SE_block
net = se_block(net)
elif attention_module == 'cbam_block': # CBAM_block
net = cbam_block(net)
else:
raise Exception("'{}' is not supported attention module!".format(attention_module))
return net
def se_block(input_feature, ratio=8):
"""Contains the implementation of Squeeze-and-Excitation(SE) block.
As described in https://arxiv.org/abs/1709.01507.
"""
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
se_feature = GlobalAveragePooling2D()(input_feature)
se_feature = Reshape((1, 1, channel))(se_feature)
assert se_feature._keras_shape[1:] == (1,1,channel)
se_feature = Dense(channel // ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')(se_feature)
assert se_feature._keras_shape[1:] == (1,1,channel//ratio)
se_feature = Dense(channel,
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')(se_feature)
assert se_feature._keras_shape[1:] == (1,1,channel)
if K.image_data_format() == 'channels_first':
se_feature = Permute((3, 1, 2))(se_feature)
se_feature = multiply([input_feature, se_feature])
return se_feature
def cbam_block(cbam_feature, ratio=8):
"""Contains the implementation of Convolutional Block Attention Module(CBAM) block.
As described in https://arxiv.org/abs/1807.06521.
"""
cbam_feature = channel_attention(cbam_feature, ratio)
cbam_feature = spatial_attention(cbam_feature)
return cbam_feature
def channel_attention(input_feature, ratio=8):
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
shared_layer_one = Dense(channel//ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
shared_layer_two = Dense(channel,
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
avg_pool = GlobalAveragePooling2D()(input_feature)
avg_pool = Reshape((1,1,channel))(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel)
avg_pool = shared_layer_one(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel//ratio)
avg_pool = shared_layer_two(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel)
max_pool = GlobalMaxPooling2D()(input_feature)
max_pool = Reshape((1,1,channel))(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel)
max_pool = shared_layer_one(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel//ratio)
max_pool = shared_layer_two(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel)
cbam_feature = Add()([avg_pool,max_pool])
cbam_feature = Activation('sigmoid')(cbam_feature)
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])
def spatial_attention(input_feature):
kernel_size = 7
if K.image_data_format() == "channels_first":
channel = input_feature._keras_shape[1]
cbam_feature = Permute((2,3,1))(input_feature)
else:
channel = input_feature._keras_shape[-1]
cbam_feature = input_feature
avg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)
assert avg_pool._keras_shape[-1] == 1
max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)
assert max_pool._keras_shape[-1] == 1
concat = Concatenate(axis=3)([avg_pool, max_pool])
assert concat._keras_shape[-1] == 2
cbam_feature = Conv2D(filters = 1,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=False)(concat)
assert cbam_feature._keras_shape[-1] == 1
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])
Using TensorFlow backend.
具体案例见:https://github.com/CodingChaozhang/CBAM-keras
背景知识
AutoML是指尽量不通过人为来设定超参数,而是使用某种学习机制,来调节这些超参数。这些学习机制包括传统的贝叶斯优化,多臂老虎机,进化算法,还有比较新的强化学习。
AutoML可以分为传统AutoML,自动调节传统的机器学习算法的参数,比如随机森林,我们来调节它的max_depth.num_trees等参数。还有一类AutoML,则专注深度学习,这类AutoML,不妨称之为深度AutoML。
与传统的AutoML的差别是,现阶段深度AutoML,会将神经网络的超参数分为两类,一类是与训练有关的超参数,比如learning rate,regularization,momentum等;还有一类超参数,则可以总结为网络结构。对网络结构的超参数自动调节,也叫Neural architecture search(nas).而针对训练的超参数,也是传统的AutoML的自动调节,称之为Hyperparameter optimization(ho)
十、 EfficientNet的提出
论文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
论文链接:https://arxiv.org/abs/1905.11946
传统的神经模型通常是任意增加CNN的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。虽然这些方法确实提高了准确性,但它们通常需要长时间的手动调优,并且仍然会产生次优的性能。而本文提出了一种新的模型缩放方法,采用一系列的尺寸缩放系数来统一缩放网络维度。通过使用这种新颖的缩放方法和AutoMl技术,称这种模型为EfficientNets,它具有更高达10倍的效果(更小、更快)。
01 EfficentNet设计思想
本文提出了一种多维度混合的模型放缩方法。本文希望找到一个同时兼顾速度和精度的模型放缩方法。为此,作者重新审视了前人提出的模型放缩的几个维度:网络深度、网络宽度、图像分辨率。而前人的文章大多是放大其中一个维度以达到更高的准确率,比如ResNet-18到RestNet-152是通过增加网络深度的方法来提高准确率。
而本文跳出了前人对放缩模型的理解,从另外一个高度去审视这些放缩维度。作者认为这三个维度之间是相互影响的并探索出了三者之间最好的组合,在此基础上提出了最新的网络Efficient。
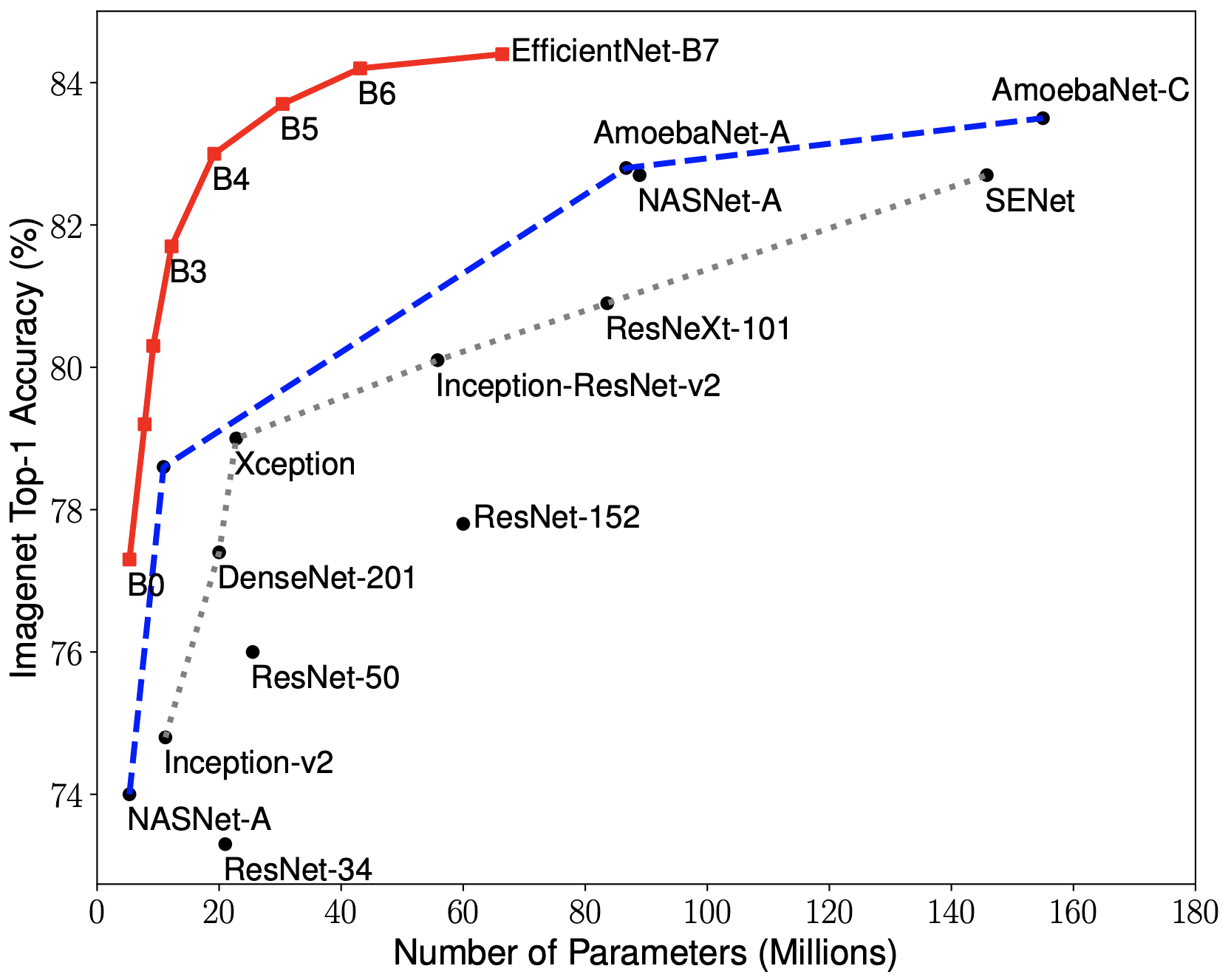
如何平衡网络的深度、宽度和分辨率来提高模型的准确率。
通常而言,提高网络的深度、宽度和分辨率来扩大模型,从而提高模型的泛化能力。

而EfficientNet是对深度、宽度和分辨率统一进行调整,作者提出了“复合相关系数”来动态提高这三个参数。
使用了AutoML的方式,利用网格搜索的形式来搜索出这个相关系数。其中,α,β,γ是使用网格搜索出来的常量,表明如何调整网络的深度、宽度和分辨率;Φ是用户自定义的相关系数,用来控制模型的扩增。

EfficientNet有8个系列,分别从b0-b7,,其中b0是baseline,b1-b7都是在b0基础上对深度、宽度和分辨率进行调整。从官方源码上,可以得到以下参数。其中,参数分别是宽度的相关系数,深度的相关系数,输入图片的分辨率和dropout的比例。这些参数如何得到的呢,就是通过刚刚介绍的AutoML进行搜索出来的。

总之,混合模型缩放方法比单一模型缩放方法对神经网络指标有更大的提升。
02 EfficientNet的实现
官方tensorflow代码链接:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
keras代码链接:https://github.com/qubvel/efficientnet
安装过程
- 1.conda create -n efficient python=3.7
- 2.conda install scikit-image
- 3.conda install keras-gpu
- 4.pip install -U efficientnet
例子:
- https://www.kaggle.com/carlolepelaars/efficientnetb5-with-keras-aptos-2019#data
- https://www.kaggle.com/raimonds1993/aptos19-efficientnet-keras-regression-lb-0-75
- https://www.kaggle.com/ratan123/aptos-keras-efficientnet-with-attention-baseline
转载:https://blog.csdn.net/Mind_programmonkey/article/details/103940511