
加载包
-
library(ggplot2)
-
library(dplyr)
-
library(Hmisc)
-
library(corrplot)
加载数据
load("brfss2013.RData")第1部分:关于数据
行为风险因素监测系统(BRFSS)是美国的年度电话调查。BRFSS旨在识别成年人口的风险因素并报告新兴趋势。例如,受访者被问及他们的饮食和每周身体活动,他们的艾滋病毒/艾滋病状况,可能的烟草使用,免疫接种,健康状况,健康日-与健康相关的生活质量,医疗保健的可及性,睡眠不足,高血压意识,胆固醇意识,慢性健康状况,饮酒,水果和蔬菜消费,关节炎负担和安全带的使用。
数据采集:
数据收集程序中进行了说明。这些数据是从美国所有50个州、哥伦比亚特区、波多黎各、关岛和美属萨摩亚、密克罗尼西亚联邦和帕劳收集的,通过进行固定电话和基于移动电话的调查。固定电话样本使用了不成比例的分层抽样(DSS),蜂窝电话受访者是随机选择的,每个受访者的选择概率相等。我们正在处理的数据集包含330个变量,2013年共有491,775个观测值。由“NA”表示的缺失值。
概 化:
样本数据应该允许我们推广到感兴趣的人群。这是对491,775名18岁或以上美国成年人的调查。它基于一个大型分层随机样本。潜在的偏见与无反应,不完整的访谈,缺失的价值观和便利偏见有关(一些潜在的受访者可能没有被包括在内,因为他们没有固定电话和手机)。
因果律:
没有因果关系可以建立,因为BRFSS是一项观察研究,只能建立变量之间的相关性/关联。
第2部分:研究问题
研究问题1:
过去30天内身心健康不好的天数分布是否因性别而异?
研究问题2:
受访者接受采访的月份与受访者自我报告的健康感知之间是否存在关联?
研究问题3:
收入和医疗保险之间有什么关联吗?
研究问题4:
吸烟、饮酒、胆固醇水平、血压、体重和中风之间有关系吗?最终,我想看看是否可以从上述变量中预测中风。
第 3 部分:探索性数据分析
研究问题1:
-
ggplot(
aes(
x=physhlth, fill=sex), data = brfss2013[!is.na(
brfss2013$sex), ]) +
-
geom_histogram(
bins=30, position = position_dodge()) + ggtitle('Number of Days Physical Health not Good in the Past
30 Days')
-
ggplot(
aes(
x=menthlth, fill=sex), data=brfss2013[!is.na(
brfss2013$sex), ]) +
-
geom_histogram(
bins=30, position = position_dodge()) + ggtitle('Number of Days Mental Health not Good in the Past
30 Days')

-
ggplot(
aes(
x=poorhlth, fill=sex), data=brfss2013[!is.na(
brfss2013$sex), ]) +
-
geom_histogram(
bins=30, position = position_dodge()) + ggtitle('Number of Days with Poor Physical Or Mental Health in the Past
30 Days')

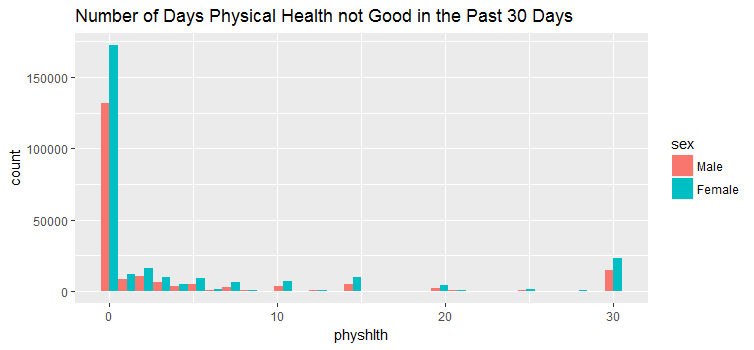
summary(brfss2013$sex)
-
## Male Female NA's
-
##201313 290455 7
以上三个数字显示了过去30天内男性和女性对身体,精神和健康不良天数的反应数据分布。我们可以看到,女性受访者远远多于男性受访者。
研究问题2:
-
by_month <- brfss2013 %>% filter(iyear=='
2013') %>% group_by(imonth, genhlth) %>% summarise(n=n())
-
ggplot(aes(x=imonth, y=n, fill = genhlth),
data = by_month[!is.na(by_month$genhlth), ]) + geom_bar(stat = 'identity', position = position_dodge()) + ggtitle('Health Perception By Month')

-
by_month1 <- brfss2013 %>% filter(iyear=='
2013') %>% group_by(imonth) %>% summarise(n=n())
-
ggplot(aes(x=imonth, y=n),
data=by_month1) + geom_bar(stat = 'identity') + ggtitle('Number of Respondents by Month')

我试图找出人们在不同月份对健康状况的反应是否不同。例如,人们是否更有可能说他们在春季或夏季身体健康?似乎没有明显的模式。
研究问题3:
-
plot(brfss2013
$income2, brfss2013
$hlthpln1, xlab =
'Income Level', ylab =
'Health Care Coverage', main =
-
'Income Level versus Health Care Coverage')

一般来说,高收入的受访者比低收入的受访者更有可能拥有医疗保健保险。
研究问题4:
为了回答这个问题,我将使用以下变量:
-
吸烟100:至少抽过100支香烟
-
avedrnk2: 过去30年平均每日酒精饮料
-
bphigh4:曾经被告知血压高
-
告诉2:曾经告诉过血液胆固醇高
-
weight2:报告的磅数重量
-
cvdstrk3:曾经被诊断出患有中风
首先,将上述变量转换为数值,并查看这些数字变量之间的任何相关性。
-
vars <-
names(brfss2013) %in%
c(
'smoke100',
'avedrnk2',
'bphigh4',
'toldhi2',
'weight2')
-
selected_brfss <- brfss2013[vars]
-
selected_brfss
$toldhi2 <-
ifelse(selected_brfss
$toldhi2==
"Yes",
1,
0)
-
selected_brfss
$smoke100 <-
ifelse(selected_brfss
$smoke100==
"Yes",
1,
0)
-
selected_brfss
$weight2 <-
as.
numeric(selected_brfss
$weight2)
-
selected_brfss
$bphigh4 <-
as.
factor(
ifelse(selected_brfss
$bphigh4==
"Yes",
"Yes", (
ifelse(selected_brfss
$bphigh4==
"Yes, but female told only during pregnancy",
"Yes", (
ifelse(selected_brfss
$bphigh4==
"Told borderline or pre-hypertensive",
"Yes",
"No"))))))
-
selected_brfss
$bphigh4 <-
ifelse(selected_brfss
$bphigh4==
"Yes",
1,
0)
-
selected_brfss <- na.
delete(selected_brfss)
-
corr.matrix <-
cor(selected_brfss)
-
corrplot(corr.matrix, main=
"\n\nCorrelation Plot of Smoke, Alcohol, Blood pressure, Cholesterol, and Weight", method=
"number")

似乎没有两个数值变量具有很强的相关性。
用于预测行程的逻辑回归
将答案“是,但女性仅在怀孕期间被告知”和“被告知临界或高血压前期”改为“是”。
-
vars1 <-
names(brfss2013) %in%
c(
'smoke100',
'avedrnk2',
'bphigh4',
'toldhi2',
'weight2',
'cvdstrk3')
-
stroke <- brfss2013[vars1]
-
stroke
$bphigh4 <-
as.
factor(
ifelse(stroke
$bphigh4==
"Yes",
"Yes", (
ifelse(stroke
$bphigh4==
"Yes, but female told only during pregnancy",
"Yes", (
ifelse(stroke
$bphigh4==
"Told borderline or pre-hypertensive",
"Yes",
"No"))))))
-
stroke
$weight2<-
as.
numeric(stroke
$weight2)
将“NA”值替换为“否”。
-
stroke
$bphigh4 <- replace(stroke
$bphigh4,
which(is.na(stroke
$bphigh4)),
"No")
-
stroke
$toldhi2 <- replace(stroke
$toldhi2,
which(is.na(stroke
$toldhi2)),
"No")
-
stroke
$cvdstrk3 <- replace(stroke
$cvdstrk3,
which(is.na(stroke
$cvdstrk3)),
"No")
-
stroke
$smoke100 <- replace(stroke
$smoke100,
which(is.na(stroke
$smoke100)),
'No')
将“NA”值替换为平均值。
mean(stroke$avedrnk2,na.rm = T)##[1] 2.209905stroke$avedrnk2 <- replace(stroke$avedrnk2, which(is.na(stroke$avedrnk2)), 2)查看将用于建模的数据。
-
head(stroke)
-
summary(stroke)
-
## bphigh4 toldhi2 cvdstrk3 weight2 smoke100 avedrnk2
-
##1 Yes Yes No 154 Yes 2
-
##2 No No No 30 No 2
-
##3 No No No 63 Yes 4
-
##4 No Yes No 31 No 2
-
##5 Yes No No 169 Yes 2
-
##6 Yes Yes No 128 No 2
-
## bphigh4 toldhi2 cvdstrk3 weight2 smoke100
-
## No :284107 Yes:183501 Yes: 20391 Min. : 1.00 Yes:215201
-
## Yes:207668 No :308274 No :471384 1st Qu.: 43.00 No :276574
-
## Median : 73.00
-
## Mean : 80.22
-
## 3rd Qu.:103.00
-
## Max. :570.00
-
## avedrnk2
-
## Min. : 1.000
-
## 1st Qu.: 2.000
-
## Median : 2.000
-
## Mean : 2.099
-
## 3rd Qu.: 2.000
-
## Max. :76.000
隐蔽到二元结果。
stroke$cvdstrk3 <- ifelse(stroke$cvdstrk3=="Yes", 1, 0)在整理和清理数据之后,现在我们可以拟合模型了。
逻辑回归模型拟合
-
train <- stroke[
1:
390000,]
-
test <- stroke[
390001:
491775,]
-
model <- glm(cvdstrk3 ~.,
family=binomial(link = 'logit'),
data=train)
-
summary(model)
-
##Call:
-
##glm(formula = cvdstrk3 ~ ., family = binomial(link = "logit"),
-
## data = train)
-
-
##Deviance Residuals:
-
## Min 1Q Median 3Q Max
-
##-0.5057 -0.3672 -0.2109 -0.1630 3.2363
-
-
##Coefficients:
-
## Estimate Std. Error z value Pr(>|z|)
-
##(Intercept) -3.2690106 0.0268240 -121.869 < 2e-16 ***
-
##bphigh4Yes 1.3051850 0.0193447 67.470 < 2e-16 ***
-
##toldhi2No -0.5678048 0.0171500 -33.108 < 2e-16 ***
-
##weight2 -0.0009628 0.0001487 -6.476 9.41e-11 ***
-
##smoke100No -0.3990598 0.0163896 -24.348 < 2e-16 ***
-
##avedrnk2 -0.0274511 0.0065099 -4.217 2.48e-05 ***
-
##---
-
##Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
-
##(Dispersion parameter for binomial family taken to be 1)
-
-
## Null deviance: 136364 on 389999 degrees of freedom
-
##Residual deviance: 126648 on 389994 degrees of freedom
-
##AIC: 126660
-
-
##Number of Fisher Scoring iterations: 6

解释我的逻辑回归模型的结果:
所有变量在统计意义上都显著。
-
所有其他变量都是平等的,被告知血压高更容易中风。
-
预测因子的负系数 - toldhi2No表明所有其他变量相等,不被告知血液胆固醇高不太可能发生中风。
-
对于重量的每一个单位变化,有一个行程(与无行程相比)的对数几率减少0.00096。
-
不吸烟 至少100支香烟,不太可能中风。
-
在过去30天内,如果平均酒精饮料每天增加一个单位,中风的对数几率将降低0.027。
anova(model, test="Chisq")
-
##Analysis of Deviance Table
-
-
##Model: binomial, link: logit
-
-
##Response: cvdstrk3
-
-
##Terms added sequentially (first to last)
-
-
-
## Df Deviance Resid. Df Resid. Dev Pr(>Chi)
-
##NULL 389999 136364
-
##bphigh4 1 7848.6 389998 128516 < 2.2e-16 ***
-
##toldhi2 1 1230.1 389997 127285 < 2.2e-16 ***
-
##weight2 1 33.2 389996 127252 8.453e-09 ***
-
##smoke100 1 584.5 389995 126668 < 2.2e-16 ***
-
##avedrnk2 1 19.9 389994 126648 7.958e-06 ***
-
##---
-
##Signif. codes: 0 '***' 0.001 '
**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
分析偏差表,我们可以看到一次添加一个变量时偏差的下降。添加 bphigh4、2、烟雾 100 可显著降低残余偏差。其他变量 weight2 和 avedrnk2 似乎对模型的影响较小,即使它们都具有较低的 p 值。
评估模型的预测能力
-
-
fitted
.results <-
predict(model,newdata=test,type='response')
-
fitted
.results <-
ifelse(fitted.results >
0.5,
1,
0)
-
-
misClasificError <-
mean(fitted.results != test$cvdstrk3)
-
print(paste('Accuracy',
1-misClasificError))
##[1] "Accuracy 0.961296978629329测试装置上的0.96精度是一个非常好的结果。
绘制 ROC 曲线并计算 AUC(曲线下的面积)。
-
library(ROCR)
-
p <-
predict(model, newdata=test, type="response")
-
pr <-
prediction(p, test$cvdstrk3)
-
prf <-
performance(pr, measure = "tpr", x.measure = "fpr")
-
plot(prf)
-
auc <-
performance(pr, measure = "auc")
-
auc <- auc
@y.values[[
1]]
-
auc

##[1] 0.7226642最后一点,当我们分析健康数据时,我们必须意识到自我报告的患病率可能存在偏见,因为受访者可能不知道他们的风险状况。因此,为了获得更精确的估计,研究人员正在使用实验室测试以及自我报告的数据。
转载:https://blog.csdn.net/tecdat/article/details/127482177